Вступление
Система персональных рекомендаций Netlfix - это комплексная система, которая может похвастаться разнообразием узкоспециализированных моделей машинного обучения, каждая из которых обслуживает свою категорию рекомендаций, начиная от "Продолжить просмотр" и заканчивая "Сегодняшней подборкой". Однако, как только мы увеличили набор алгоритмов персонализации в соответствии со спросом, затраты на обслуживание рекомендательной системы быстро выросли. Более того, было сложно внедрять новые функции от одной модели к другой, учитывая, что они обучены независимо друг от друга несмотря на одинаковые источники данных. Это привело к необходимости в новой архитектуре рекомендательной системы, в которой обучение на предпочтениях пользователя централизованно, что повышает доступность и упрощает использования этих данных между разными моделями
В частности, прошлые версии моделей извлекали информацию о предпочтениях пользователей из недавней истории взаимодействия на платформе. Однако они были ограничены коротким временным интервалом из-за затрат на обслуживание и дообучение. Это ограничение вдохновило нас разработать кардинально другую модель рекомендаций, которая будет извлекать информацию одновременно из истории взаимодействия пользователя и из общей глобальной базы данных. Такая стратегия облегчает распространение информации между моделями.
Импульс к созданию новой рекомендательной системы основан на смене парадигма в области обработки естественного языка (NLP) вследствие появления больших языковых моделей (LLM). Раньше доминировала модель, при которой существовало несколько небольших узкоспециализированных моделей. Теперь же используется одна, большая языковая модель, способная выполнять разные задачи при минимальных доработках. Основные моменты, которые можно выделить из этого изменения, заключаются в следующем:
- Подход, в центре которого находятся данные. Произошло смещение от модельно-центрированной стратегии, которая сильно зависит от инженеров, к датацентричной архитектуре. При таком подходе приоритет отдается накоплению данных высокого качества и возможности моделям самим обучаться на них.
- Ослабление контроля на обучением. Тактика предсказания моделью следующих токенов оказалась крайне эффективной. Модель использует большие объемы неразмеченных данных для самообучения и показывает высокое понимание материала
Данные
В Netflix пользователи по-разному взаимодействуют с сервисом: от обычного браузинга до увлеченного просмотра фильмов. Вместе с 300 миллионами пользователями на конец 2024 года, это превращается в сотни миллиардов взаимодействий - это число сопоставимо с количеством токенов, которое использует для обучения больших языковых моделей LLM. Как и в случае с LLM, большую роль здесь играет качество данных, а не их количество. Для эффективного использования этих данных мы применяем процесс токенизации взаимодействий, что позволяет выделять более значимые и минимизировать избыток данных
Токенизация пользовательских взаимодействий. Не все действия пользователя вносят одинаковый вклад в процесс персонализации. Токенизация позволяет определить, что является значимым "токеном" в последовательности действий. Процесс токенизации сводится к объединению смежных действий для формирования токенов более высокого уровня. Только, в свою очередь, этот процесс требует тщательного внимания относительного того, какую информацию стоит сохранять. Например, общая продолжительность просмотра может быть суммирована, чтобы оставить только необходимую информацию.
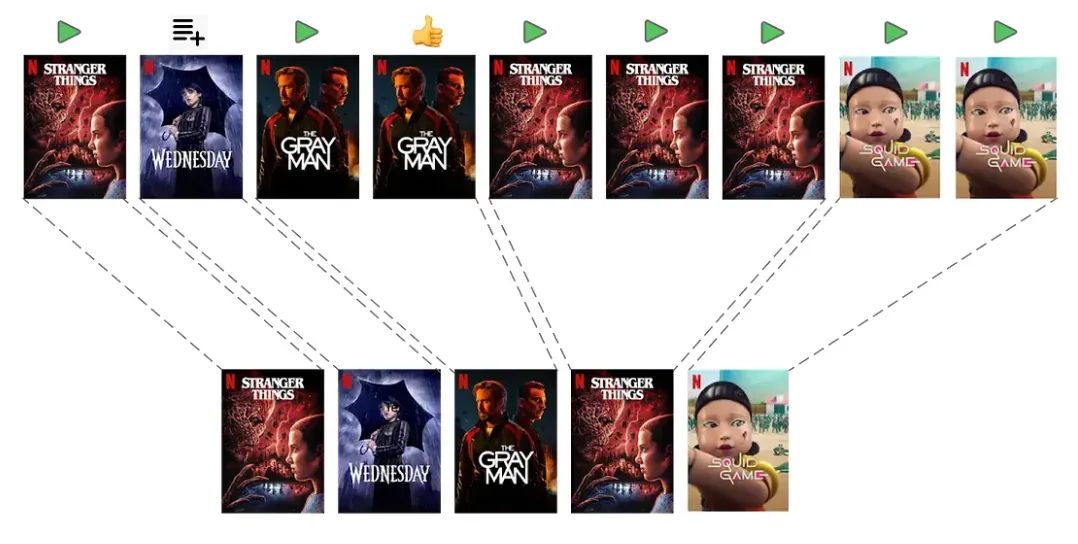 Рисунок 1. Процесс токенизации объединяет действия пользователя
Рисунок 1. Процесс токенизации объединяет действия пользователя
Этот компромисс между дейсвиями пользователя и сжатием их в последовательности схож с балансом словарем, с которым работает большая языковая модель и его контекстным окном. В нашем случае было необходимо найти баланс между длиной историй взаимодействия и детализации конкретных токенов. Слишком обобщенная токенизация повышала риск упустить ценные сигналы. в то время как чрезмерная детализация требовала повышенных ресурсов памяти и процессора.
Несмотря на подбор оптимального алгоритма токенизации, история взаимодействия пользователей может охватывать тысячи событий, что превышает уровень самоконтроля преобразующих моделей. В рекомендательный системах емкость контекстного окна ограничена сотнями событий - не из-за предела возможности моделей, а из-за того, что данные сервисы требуют критически маленькое время ответа - на уровне миллисекунд, в отличие от других LLM приложений, где допускается более длительное время ответа (на уровне секунд).
Чтобы решить эту пробелу во время обучения моделей, мы внедрили 2 принципа:
- Механизм рассеянного внимания. Понижение внимания модели с помощью низкорангового сжатия позволяет ей увеличить емкость контекстного окна. Тогда модель способна обрабатывать сотни событий и увеличивать точность предсказаний долгосрочных предпочтений.
- Выборка методом скользящего окна. Перед началом обучения модели мы убираем из истории взаимодействия пересекающиеся токены, что позволяет модели видеть более обширное контекстное окно и обучаться на непрерывной последовательности действий Эти методы вместе позволили нам одновременно получить детализацию данных, поддержку долгосрочного планирования и детальное обучение модели с возможностью масштабирования всей системы.
Информация в Токене. Мы обсудили, что первая часть процесса токенизации основана на структурировании последовательности пользовательских действий. Следующим же шагов является определение полезной информации внутри каждого токена. В отличие от LLM, которые используются векторы в многомерном пространстве для представления входных данных, наши пользовательские действия содержать в себе разные виды информации. Они содержат как атрибуты действия (язык, время, продолжительность, тип устройства), так и информацию о контенте (уникальный номер слота, жанр, страна выпуска). Большинство этих атрибутов, особенно категории контента, напрямую встроены в модели. В то же время, некоторые характеристики требуют особенного внимания. К примеру, временные метки нужно фиксировать абсолютно и относительно. Абсолютные метки в том числе важны для понимания поведения, зависящего от времени.
Для повышения точности прогноризования рекомендательном системы мы организуем характеристики токенов на 2 категории:
- Характеристики, доступные во время запроса. Например, время логина, тип устройства, геопозиция.
- Характеристики, доступные после взаимодействия. Они показывают длительность взаимодействия, выбранный элемент.
Для того чтобы предсказать следующее взаимодействие, мы комбинируем характеристики запроса текущего шага с характеристиками, доступными после взаимодействия, предыдущего шага. Эта комбинация гарантирует, что каждый токен отражает свежий контекст и поведенческий фактор пользователя.
Цель и Архитектура модели
Как упоминалось ранее, наше поведение моделей по умолчанию использует регрессивный подход к предсказанию следующих токенов, напомищающий подход GPT. Однако нам пришлось изменить некоторые аспекты, так как обработка языковых задач отличается от задач рекомендательных систем.
Во-первых, во время предтренировок стандартных LLM, таких как GPT, каждый токен имеет свой конкретный вес. В нашем случае, не все действия пользователя одинаково важны. Например, просмотр 5 минутного реклама ролика не то же самое, что просмотр двухчасового фильма. Более сложная задача возникает, когда нужно согласовать длительное удовлетворение пользователя с конкретными взаимодействиями.
Во-вторых, мы можем использовать несколько полей в наших входных данных в качестве вспомогательных целей прогнозирования в дополнение к прогнозированию следующего идентификатора элемента, который остается основной целью. Например, мы можем вывести жанры из элементов в исходной последовательности и использовать эту последовательность жанров в качестве вспомогательной цели. Этот подход закрывает несколько аспектов: он действует как регулятор, уменьшая переобучение при прогнозировании идентификаторов элементов с шумом, предоставляет дополнительную информацию о намерениях пользователей или долгосрочных жанровых предпочтениях и, при иерархической структуре, может повысить точность прогнозирования идентификатора целевого элемента. Сначала прогнозируя вспомогательные цели, такие как жанр или язык оригинала, модель эффективно сужает список кандидатов, упрощая последующее прогнозирование идентификатора элемента.
В дополнение к инфаструктурным особенностям, связанных с тренировкой LLM, есть еще одна проблема - продвижение и рекомендации только что созданной сущности.
В Netflix наша задача - развлекать мир. Новые заголовки попадают в каталог быстро. Поэтому базовые модели рекомендаций требуют возможности «холодного запуска», что означает, что модели должны оценивать предпочтения членов по отношению к недавно выпущенным продуктам до того, как кто-либо с ними ознакомится. Для этого наша структура обучения базовых моделей построена с использованием следующих двух возможностей: инкрементальное обучение и возможность делать выводы по не проиндексированным объектам.
- Базовые модели обучаются на обширных наборах данных, включая историю взаимодействий каждого участника, что делает частое переобучение нецелесообразным. Однако наш каталог и предпочтения участников постоянно меняются. В отличие от крупных языковых моделей, которые можно постепенно обучать с помощью стабильного словаря токенов, наши модели рекомендаций требуют новых вложений для новых названий, что необходимо для расширения слоев вложений и компонентов вывода. Для решения этой проблемы мы запускаем новые модели, повторно используя параметры из предыдущих моделей и инициализируя новые параметры для новых названий. Например, вложения новых названий могут быть инициализированы путем добавления небольшого случайного шума к существующим средним вложениям или путем использования взвешенной комбинации вложений похожих названий на основе метаданных. Такой подход позволяет новым названиям начинать с релевантных вложений, что ускоряет точную настройку. На практике метод инициализации становится менее важным, когда для точной настройки используется больше данных о взаимодействии членов.
- Работа с неиндесированными сущностями: даже при инкрементальном обучении не всегда гарантируется эффективное обучение на новых сущностях (например, недавно выпущенных названиях). Также возможно, что будут некоторые новые сущности, которые не включены/не видны в обучающих данных, даже если мы часто настраиваем базовые модели. Поэтому также важно позволить базовым моделям использовать метаданные объектов и входных данных, а не только данные о взаимодействии членов. Таким образом, наша базовая модель сочетает в себе как обучаемые вложения идентификаторов элементов, так и обучаемые вложения из метаданных. Следующая диаграмма иллюстрирует эту идею.
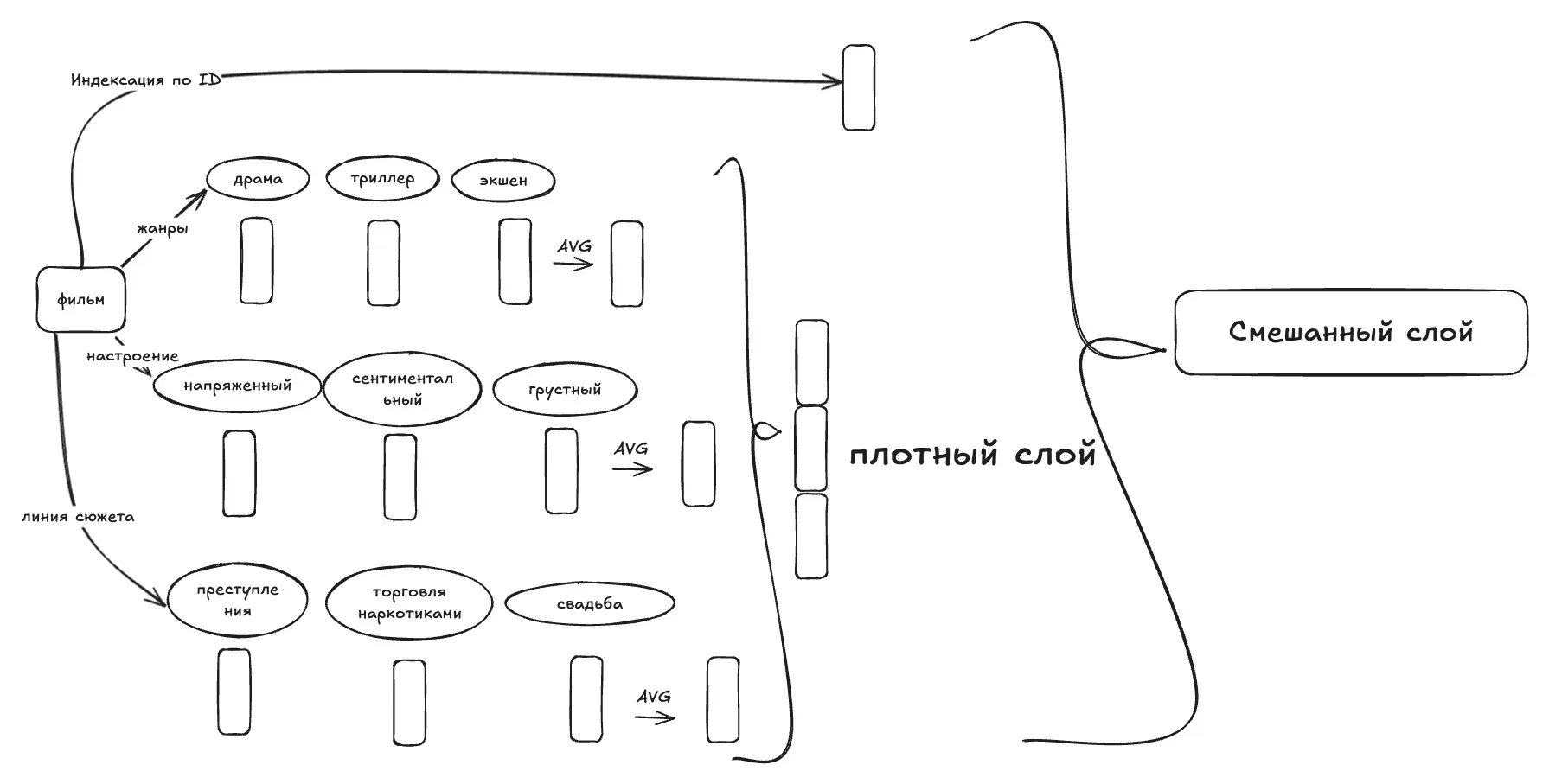 Чтобы создать готовый заголовок, мы комбинируем это вложение на основе метаданных с полностью обучаемым вложением на основе ID с помощью смешивающего слоя. Вместо простого суммирования этих вложений мы используем механизм внимания, основанный на «возрасте» сущности. Такой подход позволяет новым заголовкам с ограниченными данными взаимодействия в большей степени полагаться на метаданные, в то время как устоявшиеся заголовки могут в большей степени полагаться на вложения на основе ID. Поскольку названия с похожими метаданными могут иметь разное вовлечение пользователей, их вложения должны отражать эти различия. Введение некоторой случайности во время обучения побуждает модель учиться на метаданных, а не полагаться исключительно на вложения на основе идентификаторов. Этот метод гарантирует, что недавно запущенные или предзапущенные названия будут иметь разумные вложения даже при отсутствии данных о взаимодействии пользователей.
Чтобы создать готовый заголовок, мы комбинируем это вложение на основе метаданных с полностью обучаемым вложением на основе ID с помощью смешивающего слоя. Вместо простого суммирования этих вложений мы используем механизм внимания, основанный на «возрасте» сущности. Такой подход позволяет новым заголовкам с ограниченными данными взаимодействия в большей степени полагаться на метаданные, в то время как устоявшиеся заголовки могут в большей степени полагаться на вложения на основе ID. Поскольку названия с похожими метаданными могут иметь разное вовлечение пользователей, их вложения должны отражать эти различия. Введение некоторой случайности во время обучения побуждает модель учиться на метаданных, а не полагаться исключительно на вложения на основе идентификаторов. Этот метод гарантирует, что недавно запущенные или предзапущенные названия будут иметь разумные вложения даже при отсутствии данных о взаимодействии пользователей.
Прикладные задачи и вызовы
Наша базовая рекомендательная модель спроектирована так, чтобы понимать долгосрочные предпочтения пользователей, и может использоваться различными способами в прикладных системах:
Прямое использование как предсказательной модели
Модель изначально обучена предсказывать следующий объект, с которым будет взаимодействовать пользователь. Она включает несколько «голов предсказания» для разных задач, например прогнозирования предпочтений по жанрам. Эти возможности могут напрямую применяться для решения различных бизнес-задач.
Использование эмбеддингов
Модель формирует полезные эмбеддинги для пользователей и объектов — видео, игр, жанров и т.д. Эти эмбеддинги вычисляются в пакетных заданиях и сохраняются для применения как в офлайн-, так и в онлайн-приложениях. Они могут выступать признаками (features) в других моделях или использоваться для генерации кандидатов, например при подборе релевантных заголовков для пользователя.
Однако есть важный нюанс: пространство эмбеддингов имеет произвольные, непонятные человеку измерения и несовместимо между разными запусками обучения модели. Это создаёт сложности для прикладных систем, которым приходится адаптироваться к каждому переобучению и повторному развёртыванию, рискуя ошибками из-за неверных предположений о структуре эмбеддингов. Чтобы решить эту проблему, мы применяем ортогональное низкоранговое преобразование для стабилизации пространства пользовательских и предметных эмбеддингов. Это обеспечивает согласованность значений измерений эмбеддингов, даже если базовая модель переобучается и развёртывается заново.
Тонкая настройка на специфичных данных
Адаптивность модели позволяет дообучать её на данных конкретных приложений. Пользователи могут интегрировать как всю модель, так и отдельные её подграфы в свои собственные модели, дообучая их с меньшими затратами данных и вычислительных ресурсов. Такой подход обеспечивает качество, сопоставимое с предыдущими моделями, даже несмотря на то, что изначальная базовая модель требовала значительных ресурсов.
Масштабирование базовых моделей для рекомендаций Netflix
Масштабируя нашу базовую модель для рекомендательных систем Netflix, мы опираемся на опыт успешного развития больших языковых моделей (LLMs). Подобно тому, как LLM показали эффективность масштабирования для повышения качества работы, мы видим, что масштабирование является критически важным и для генеративных рекомендательных задач.
Успешное масштабирование требует надёжной оценки, эффективных алгоритмов обучения и значительных вычислительных мощностей. Оценка должна чётко выявлять различия в качестве модели и определять направления улучшений. Масштабирование включает расширение данных, моделей и контекста — с использованием вовлечённости пользователей, внешних отзывов, мультимедийных ресурсов и высококачественных эмбеддингов.
Наши эксперименты подтверждают, что закон масштабирования применим и к нашей базовой рекомендательной модели: с увеличением объёмов данных и размера модели мы стабильно наблюдаем рост качества.
Заключение
Наша базовая модель для персонализированных рекомендаций является значительным шагом к созданию единой, ориентированной на данные системы, которая использует масштабные массивы данных для повышения качества рекомендаций для наших пользователей.
Подход опирается на опыт больших языковых моделей (LLMs), в частности на принципы полунаблюдаемого обучения и сквозного (end-to-end) тренинга, с целью максимально эффективно использовать огромные объёмы неразмеченных данных о пользовательских взаимодействиях.
Решая специфические задачи, такие как проблема холодного старта и предвзятость в подаче контента, модель при этом учитывает принципиальные различия между задачами обработки языка и задачами рекомендаций.
Базовая модель открывает возможности для различных прикладных сценариев — от прямого применения в качестве предсказательной модели до генерации эмбеддингов пользователей и объектов для других приложений, а также может быть дообучена для конкретных случаев использования. Мы уже наблюдаем обнадёживающие результаты при интеграции модели в прикладные системы.
Переход от множества узкоспециализированных моделей к более комплексной системе является важным и перспективным этапом развития в области персонализированных рекомендательных систем.